Data Feed
The data feed is the primary method used to synchronize data from the telematics system to another system using the API. The GetFeed method can be polled at intervals to get new and updated data from the system. The feed API works with a token that is passed on every request and sent back with the payload on every response. This allows Geotab to track “up to which point in time” we have already sent the receiver data. It also allows the receiver to stop and seamlessly resume the data feed.
Lightweight Incremental Poll
The feed API is designed to be lightweight and scalable. There is virtually no cost on Geotab’s side for a poll request that yields no data. For example, a poll request when the round trip has no GPS coordinates will return no payload data. The requests themselves, the amount of processing time taken, and the amount of data returned via the internet are all extremely small.
Here is a small trace showing < 100 bytes for an empty poll request with response time of 19ms. The last request contains a payload with 2 GPS coordinates.
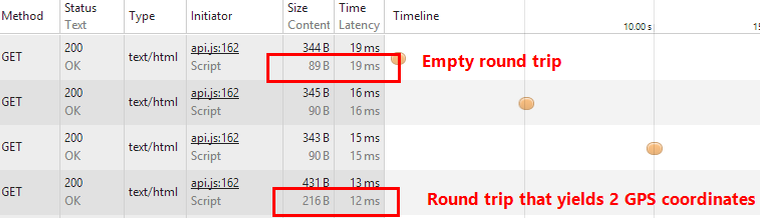
The polling frequency is dictated by the requirements of the integration. It could be as infrequent as once a day or as frequent as every few seconds.
Dealing with Volume
In each request the caller can specify the maximum number of data points that can be returned in a request. This allows the caller to have control over the maximum size of the responses. This value can be adjusted down from the default of 50,000 — with fewer data points yielding a faster response time. When the limit is reached, the response will be returned with the payload and a token which can be used to specify the point in time from which the next request should start.
The request-response approach also allows for incremental processing. For example, if there were a large backlog of data, the caller would be able to process the chunks of data at its own rate until the backlog of data has been cleared.
The API can be consumed by small and large customers alike. Larger customers can consume tens of millions of records per day via the API.
Searching
The data feed was designed to be an efficient means of getting a continuous feed of new data from a given token. When a feed is first started it is possible to provide search criteria with a “from date” argument. This specifies the token that will be used to start the feed. This will guarantee that the feed will start at a point that will include any data that is at or after the “from date” argument, but may also include data timestamped before the “from date” argument. For example when performing a “TripSearch” and setting “IncludeOverlappedTrips” to True.
While “from date” is supported, “to date” is not. The feed is not designed to return data within discrete dates. If you wish to obtain data in a particular date range, then use the standard Get methods associated with the entity search objects. If a version is specified, then the argument “from date” is ignored.
Do not pass a search to any feed unless it specifically is mentioned in the GetFeed method documentation.
Caching to Improve Performance
It may be required to populate nested entities of data retrieved via the feed. Entities that are static or semi-static will respond well to caching.
For example, status data and diagnostics are separate entities in the system. Status data references a diagnostic. Status data returned by the feed will only have the ID property of the diagnostic populated. If the diagnostic is required by your process then you must get the diagnostic in a separate API call and populate it in the status data record.
This is a good example of where caching can be implemented to improve efficiency, as diagnostic data rarely changes. A cache of diagnostics can be held in memory, refreshed at some interval of your choosing (24 hours, 12 hours, etc.) and may vary depending on the entity type being cached. Entities that may respond well to caching include Unit of Measure, Diagnostic, Source, Device and User.
Active vs Calculated
There are two types of data that can be retrieved using a data feed: active data and calculated data.
Active data are records that are received from a source, usually a Go device or user input. They are not created based off of other data. These records are static; once received, they are typically not updated and will not be removed by the system. For example, as new GPS (LogRecord) data arrives from a device, it is stored by the system.
Calculated data are records generated automatically by the system, usually in response to active data that has recently been received. These records are dynamic; an existing calculated data record can be edited and removed by the system automatically, based on new active data that was received. This processing happens in real-time as new active data is received by the system. For example, as new GPS and engine data arrives from a device, it is processed to create new ExceptionEvents or edit/remove existing ExceptionEvents.
Active Data Feeds (Only new data.)
AnnotationLog
Audit
CustomData
DVIRLog
DebugData
Device
Diagnostic
DriverChange
DutyStatusLog
FaultData
IoxAddOn
LogRecord
Route
Rule
ShipmentLog
StatusData
TextMessage
Trailer
TrailerAttachment
User
Zone
Calculated data feeds (New data and updated data from the past.)
ChargeEvent
ExceptionEvent
FillUp
FuelTaxDetail
FuelUsed
Trip
Invalidated Data
As calculated data is processed in real time, the state of the data can change causing it to become invalidated. There are a few reasons why calculated data can become invalid or need to be updated by the system.
A trip or exception is in progress
The system receives new data that invalidates previous data
Manual reprocessing was triggered
Trips
Trips are calculated data. As new data arrives for a trip currently in progress, the older data for the trip is dropped from the database. The dropped data is then replaced with the newer, more current trip data. The updated trip data will have a different trip ID than the previous record of the trip. Thus the “unique trip ID” cannot be used to match an updated trip to an earlier state.
The unique “key” (used to associate the earlier “version” of the trip in progress to the updated trip) consists of the deviceId and the trip’s stop date. Most of the time, a trip which is in progress will have its stop date continuously updated until the trip has actually ceased (ignition off). An old trip will be replaced with a new trip if:
- the trips’ deviceId are the same AND
- the start dates are the same AND
- the stop dates are different AND
- the new trip’s stop duration is 0
Exception Events
Like trips, exception events are calculated data. As the system receives updated device data, that data is processed and evaluated against the Rules set up in the system. Exception events that are in progress will be updated by the system and will retain the same unique id. Exception events can be invalidated and dropped from the database when a manual process is triggered. Reprocessed exception events will have a new unique id.
HOS and DVIR Feeds
The HOS and DVIR related objects under the “Active data feeds” (DutyStatusLog, DVIRLog, AnnotationLog, ShipmentLog) are likely to be edited on a frequent basis. An example is a “DutyStatusLog” that was created (Add) at the beginning of the day with an “ON” duty status, and then edited (Set) to add the “verifyDateTime” at the end of the day.
Each time one of these data records is manipulated, it will retain its original unique GUID “Id” but will receive an incremented “version”. This way you can match new feed records to existing data you obtained from an earlier feed request.
Next Steps
Once you have a basic understanding of how the Data Feed works you can read more about the GetFeed method and it’s parameters in the API Reference or try out the JavaScript and .Net data feed examples.
FAQ
Why do I have to poll data, can’t you push it to me?
A push-based approach would require Geotab to connect to another organization and this invariably means firewall traversal is required. To accomplish this, network administrators will need to be involved and will be required to maintain the process. This is very often a cumbersome process and sometimes disallowed due to security risks. Geotab wants to provide a zero configuration solution. The poll-based approach avoids these issues because all traffic is initiated from within your network, secured via SSL. No certificates need to be installed, no firewalls configured, and no other onerous security requirements are necessary.
There are definitely advantages and disadvantages to both approaches. However, in our experience, we have found the polling based approach is scalable, solves practical network problems, requires zero configuration, and meets the needs of our customers.